Data Science
What is data science? It is a bunch of different jobs bunched together and given the tie of AI to make a company sound innovative. As a data scientist, I consider myself a solver of probabilistic problems. I have business cases that require some sort of probabilistic solution.
Exploratory Data Analysis
Exploratory data analysis, or EDA for short, is the bread and butter of most data scientists. It is being an analyst on steroids. EDA can be everything from notebooks and CSV files to machine-learning proof of concepts.
Things to keep in mind in the EDA.
- When you have a "finding," you should try your best to disprove it.
- Beware of data myopia, seeing only a narrow part of the data you are working on.
- Notebooks are notebooks, not code. Actual reusable code should be in Python files, not notebooks.
Start Small when doing Modeling.
A big issue in data science and machine learning engineering is that the feedback loop is too long, breaking the development flow. Therefore, when you start to work with something new or unfamiliar concept, try to limit the levels of data as much as possible. It is much more rewarding to your upskilling and development speed to mock something 5 times than doing it with real data once. Another gain is that you reduce the complexity of the problem you are trying to solve. By having the complexity of code and model separate from the complexity in data, you can much more easily understand each problem and then move on to the next one.
Experience and skill are the things driving velocity, so focus on gaining as much repetition as possible when experimenting, and then you can move to bigger datasets. This article is a good explanation on the phenomenon.
Uncertainty
- Aleatoric nuncertainty: Label Noise (Labels have been flipped to other classes)
- Epistemic uncertainty: Model Noise (erroneous predicted probabilities)
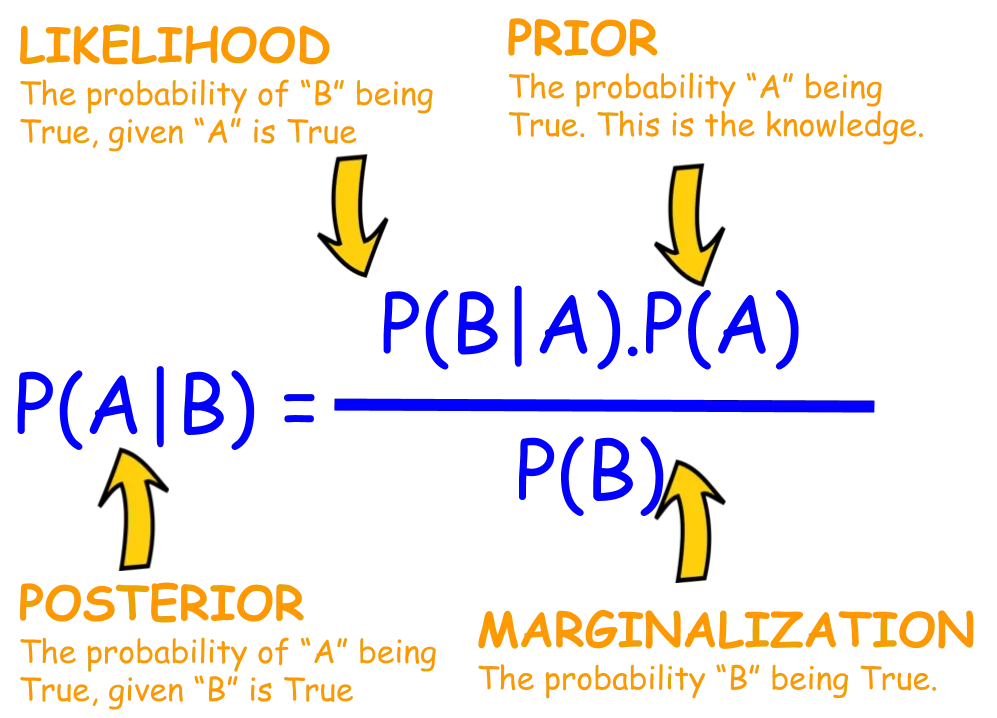
Bayes Theorem
Links
- Endless demand for insight
- Topological Data Analysis Also a more comprehensive document on it here
- I found Eugene Yan´s insights and articles to be quite helpful and full of exciting thoughts.
- Articles on Applied ML
- When too much evidence is bad, an Interesting article argues that when the results are too good to be true, then it probably is. If there are some fantastic numbers and everything is correct, then something is off. We expect that data shows some inconsistencies.
- Statistical methods
- Data Science the Hard Parts is a good starting point to look at data science as a manager and stakeholder problem, rather than a technical and scientific issue.
Thoughts
- A machine learning (ML) model is a software artifact “compiled” from data.
- Selection bias: Training data is not representative of the real world. The distribution of training data does not match real-world deployment distribution. This happens for a lot of reasons. Examples are Time, over-filtering data, rare events, and convenience-based collections. (Only survey your friends or in a single location.)
- A famous empiricist once said, “With great power comes great responsibility.” In Bayesian terms, the stronger we make our model–following the excellent precepts of Jeffreys and Jaynes–the more able we will be to find the model’s flaws and thus perform scientific learning.
- Conformal predictions is a machine learning framework that provides a way to quantify the uncertainty of predictions made by a model. It allows you to assign confidence measures to individual predictions, indicating how likely the predictions are to be correct.
- See if you can overfit. If you can overfit, you can predict.
- A data scientist´s main enemy is not adversarial stakeholders or bad data in itself. It is the fast and chaotic nature of business and the demand for quick and dirty insights that a rigorous analytical framework is not suited for.